Introduire le NLP et le text mining dans les recherches en sciences de l'éducation
Séminaire de l'IDHN, le 31 mai à 10h30
Séminaire en ligne
sur zoom
De l'intérêt de l'analyse textuelle pour l'analyse des professionnalités enseignantes
Muriel Epstein, EMA, CY Cergy Paris Université
Au cours de recherches passées, nous avons construit, avec Nicolas Bourgeois, une méthode quantitative inductive, basée sur l'analyse de champs lexicaux (topic modeling), pour étudier les blogs des enseignants. Cette approche permet d'acquérir de nouvelles connaissances sur les préoccupations des enseignants dans des domaines attendus, tels que leur discipline ou leur usage de la technologie numérique, mais aussi dans des domaines inattendus, tels que les questions de code vestimentaire ou les attentats terroristes. En perspective de ce séminaire, nous proposerons de montrer comment les méthodes d'analyses textuelles développées peuvent être appliquées à l'analyse des productions de GPS (Gestion Professionnelle des Situations), plateforme développée à EMA pour former les enseignants.
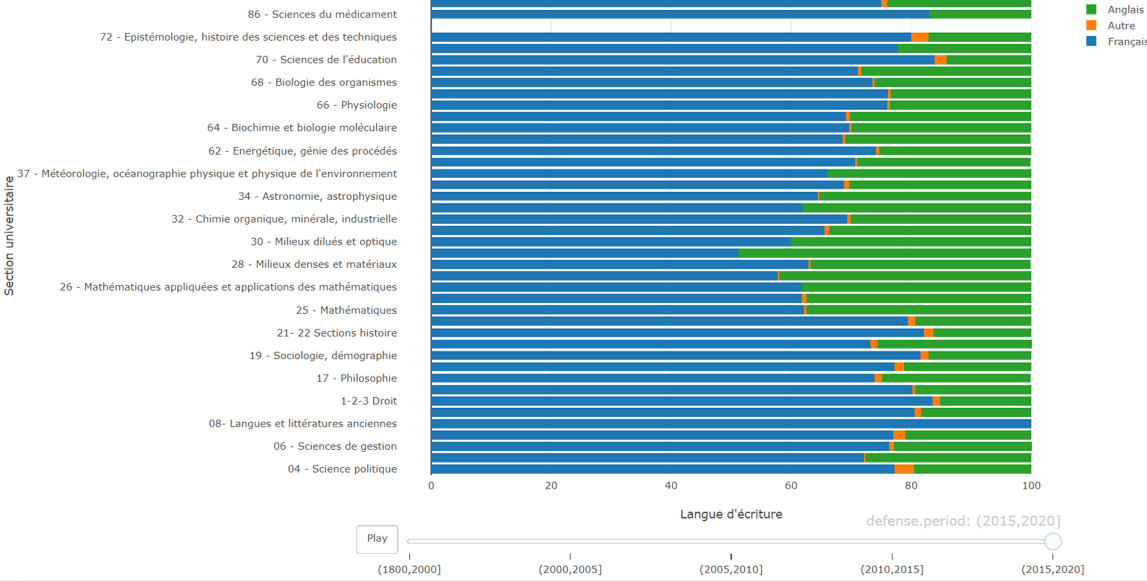
Les métadonnées de theses.fr : une source de données suffisamment fiable pour l'analyse de l'évolution des recherches doctorales au cours des 30 dernières années ?
Matthieu Cisel, IDHN, CY Cergy Paris Université
On trouve dans de nombreux pays des répertoires de thèses de doctorat conçus pour fonctionner à l’échelle nationale ; c’est le cas en France avec le site
theses.fr, qui comporte près des données sur près de 500.000 thèses soutenues à partir des années 1980, et son archive TEL, qui recense plus de 100.000 manuscrits. L’analyse des métadonnées des thèses de doctorat (langue, discipline, directeur de thèse, etc.) à une telle échelle permet d’analyser facilement des phénomènes macrosociaux (évolution de la langue d’écriture selon les disciplines, du taux de direction, etc.). Face à un tel projet, de nombreux obstacles se dressent néanmoins : manque de fiabilité des métadonnées recensées (langue d’écriture), manque de standardisation de certaines variables (chaque doctorant définissant lui-même sa discipline), fusion et scission d’établissements (qui perturbent les analyses par institutions), etc. Au-delà des résultats préliminaires de nos analyses, nous proposons, dans ce séminaire à visée méthodologique, de présenter différentes techniques mobilisées pour nettoyer notre jeu de données : machine learning, text mining, traitement automatique du langage naturel. Nous mènerons une discussion sur la robustesse des résultats que l’on peut tirer de l’exploitation du jeu de données que nous avons scrapé.